API: pytsk.gradient_descent
This package contains all the APIs you need to build and train a fuzzy neural networks.
pytsk.gradient_descent.antecedent
- class AntecedentGMF(in_dim, n_rule, high_dim=False, init_center=None, init_sigma=1.0, eps=1e-08)
Parent:
torch.nn.ModuleThe antecedent part with Gaussian membership function. Input: data, output the corresponding firing levels of each rule. The firing level \(f_r(\mathbf{x})\) of the \(r\)-th rule are computed by:
\[\begin{split}&\mu_{r,d}(x_d) = \exp(-\frac{(x_d - m_{r,d})^2}{2\sigma_{r,d}^2}),\\ &f_{r}(\mathbf{x})=\prod_{d=1}^{D}\mu_{r,d}(x_d),\\ &\overline{f}_r(\mathbf{x}) = \frac{f_{r}(\mathbf{x})}{\sum_{i=1}^R f_{i}(\mathbf{x})}.\end{split}\]- Parameters
in_dim (int) – Number of features \(D\) of the input.
n_rule (int) – Number of rules \(R\) of the TSK model.
high_dim (bool) – Whether to use the HTSK defuzzification. If
high_dim=True, HTSK is used. Otherwise the original defuzzification is used. More details can be found at [1]. TSK model tends to fail on high-dimensional problems, so sethigh_dim=Trueis highly recommended for any-dimensional problems.init_center (numpy.array) – Initial center of the Gaussian membership function with the size of \([D,R]\). A common way is to run a KMeans clustering and set
init_centeras the obtained centers. You can simply runpytsk.gradient_descent.antecedent.antecedent_init_centerto obtain the center.init_sigma (float) – Initial \(\sigma\) of the Gaussian membership function.
eps (float) – A constant to avoid the division zero error.
- init(self, center, sigma)
Change the value of
init_centerandinit_sigma.- Parameters
center (numpy.array) – Initial center of the Gaussian membership function with the size of \([D,R]\). A common way is to run a KMeans clustering and set
init_centeras the obtained centers. You can simply runpytsk.gradient_descent.antecedent.antecedent_init_centerto obtain the center.sigma (float) – Initial \(\sigma\) of the Gaussian membership function.
- reset_parameters(self)
Re-initialize all parameters.
- forward(self, X)
Forward method of Pytorch Module.
- Parameters
X (torch.tensor) – Pytorch tensor with the size of \([N, D]\), where \(N\) is the number of samples, \(D\) is the input dimension.
- Returns
Firing level matrix \(U\) with the size of \([N, R]\).
Parent:
torch.nn.ModuleThe antecedent part with Gaussian membership function, rules will share the membership functions on each feature [2]. The number of rules will be \(M^D\), where \(M\) is
n_mf, \(D\) is the number of features (in_dim).- Parameters
in_dim (int) – Number of features \(D\) of the input.
n_mf (int) – Number of membership functions \(M\) of each feature.
high_dim (bool) – Whether to use the HTSK defuzzification. If
high_dim=True, HTSK is used. Otherwise the original defuzzification is used. More details can be found at [1]. TSK model tends to fail on high-dimensional problems, so sethigh_dim=Trueis highly recommended for any-dimensional problems.init_center (numpy.array) – Initial center of the Gaussian membership function with the size of \([D,M]\).
init_sigma (float) – Initial \(\sigma\) of the Gaussian membership function.
eps (float) – A constant to avoid the division zero error.
Change the value of
init_centerandinit_sigma.- Parameters
center (numpy.array) – Initial center of the Gaussian membership function with the size of \([D,M]\).
sigma (float) – Initial \(\sigma\) of the Gaussian membership function.
Re-initialize all parameters.
Forward method of Pytorch Module.
- Parameters
X (torch.tensor) – Pytorch tensor with the size of \([N, D]\), where \(N\) is the number of samples, \(D\) is the input dimension.
- Returns
Firing level matrix \(U\) with the size of \([N, R], R=M^D\):.
- class AntecedentTriMF(in_dim, n_rule, init_center=None, init_left_dist=3.0, init_right_dist=3.0, eps=1e-08)
Parent:
torch.nn.ModuleThe antecedent part with triangle membership function. Input: data, output the corresponding firing levels of each rule. The firing level \(f_r(\mathbf{x})\) of the \(r\)-th rule are computed by:
\[\begin{split}&\mu_{r,d}(x_d) = \max(0, \min(\frac{1}{d^{(l)}_{r,d}}x + 1 - \frac{m_{r,d}}{d^{(l)}_{r,d}}, -\frac{1}{d^{(r)}_{r,d}}x + 1 + \frac{m_{r,d}}{d^{(r)}_{r,d}})),\\ &f_{r}(\mathbf{x})=\prod_{d=1}^{D}\mu_{r,d}(x_d),\\ &\overline{f}_r(\mathbf{x}) = \frac{f_{r}(\mathbf{x})}{\sum_{i=1}^R f_{i}(\mathbf{x})},\end{split}\]where \(d^{(l)}_{r,d}\)/\(d^{(r)}_{r,d}\) is the distance between the center and the left/right vertex of the triangle membership function, respectively. A simple schematic is shown below:
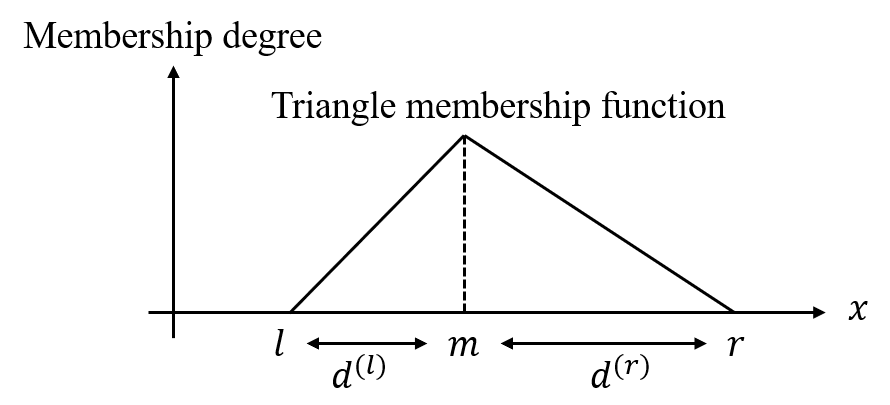
- Parameters
in_dim (int) – Number of features \(D\) of the input.
n_rule (int) – Number of rules \(R\) of the TSK model.
init_center (numpy.array) – Initial center of the triangle membership function with the size of \([D,M]\).
init_left_dist (float) – Initial \(d^{(l)}\) of the triangle membership function.
init_right_dist (float) – Initial \(d^{(r)}\) of the triangle membership function.
eps (float) – A constant to avoid the division zero error.
- init(self, center, left_dist, right_dist)
Change the value of
init_center,init_left_distandinit_right_dist.
- Parameters
init_center (numpy.array) – Initial center of the triangle membership function with the size of \([D,R]\).
left_dist (float) – Initial \(d^{(l)}\) of the triangle membership function.
right_dist (float) – Initial \(d^{(r)}\) of the triangle membership function.
- reset_parameters(self)
Re-initialize all parameters.
- forward(self, X)
Forward method of Pytorch Module.
- Parameters
X (torch.tensor) – Pytorch tensor with the size of \([N, D]\), where \(N\) is the number of samples, \(D\) is the input dimension.
- Returns
Firing level matrix \(U\) with the size of \([N, R]\):.
Parent:
torch.nn.ModuleThe antecedent part with triangle membership function, rules will share the membership functions on each feature [2]. The number of rules will be \(M^D\), where \(M\) is
n_mf, \(D\) is the number of features (in_dim).- Parameters
in_dim (int) – Number of features \(D\) of the input.
n_mf (int) – Number of membership functions \(M\) of each feature.
init_center (numpy.array) – Initial center of the triangle membership function with the size of \([D,M]\).
init_left_dist (float) – Initial \(d^{(l)}\) of the triangle membership function.
init_right_dist (float) – Initial \(d^{(r)}\) of the triangle membership function.
eps (float) – A constant to avoid the division zero error.
Change the value of
init_center,init_left_distandinit_right_dist.
- Parameters
init_center (numpy.array) – Initial center of the triangle membership function with the size of \([D,M]\).
left_dist (float) – Initial \(d^{(l)}\) of the triangle membership function.
right_dist (float) – Initial \(d^{(r)}\) of the triangle membership function.
Re-initialize all parameters.
Forward method of Pytorch Module.
- Parameters
X (torch.tensor) – Pytorch tensor with the size of \([N, D]\), where \(N\) is the number of samples, \(D\) is the input dimension.
- Returns
Firing level matrix \(U\) with the size of \([N, R], R=M^D\):.
- antecedent_init_center(X, y=None, n_rule=2, method='kmean', engine='sklearn', n_init=20)
This function run KMeans clustering to obtain the
init_centerforAntecedentGMF().>>> init_center = antecedent_init_center(X, n_rule=10, method="kmean", n_init=20) >>> antecedent = AntecedentGMF(X.shape[1], n_rule=10, init_center=init_center)
- Parameters
X (numpy.array) – Feature matrix with the size of \([N,D]\), where \(N\) is the number of samples, \(D\) is the number of features.
y (numpy.array) – None, not used.
n_rule (int) – Number of rules \(R\). This function will run a KMeans clustering to obtain \(R\) cluster centers as the initial antecedent center for TSK modeling.
method (str) – Current version only support “kmean”.
engine (str) – “sklearn” or “faiss”. If “sklearn”, then the
sklearn.cluster.KMeans()function will be used, otherwise thefaiss.Kmeans()will be used. Faiss provide a faster KMeans clustering algorithm, “faiss” is recommended for large datasets.n_init (int) – Number of initialization of the KMeans algorithm. Same as the parameter
n_initinsklearn.cluster.KMeans()and the parameternredoinfaiss.Kmeans().
pytsk.gradient_descent.tsk
- class TSK(in_dim, out_dim, n_rule, antecedent, order=1, eps=1e-08, precons=None)
Parent:
torch.nn.ModuleThis module define the consequent part of the TSK model and combines it with a pre-defined antecedent module. The input of this module is the raw feature matrix, and output the final prediction of a TSK model.
- Parameters
in_dim (int) – Number of features \(D\).
out_dim (int) – Number of output dimension \(C\).
n_rule (int) – Number of rules \(R\), must equal to the
n_ruleof theAntecedent().antecedent (torch.Module) – An antecedent module, whose output dimension should be equal to the number of rules \(R\).
order (int) – 0 or 1. The order of TSK. If 0, zero-oder TSK, else, first-order TSK.
eps (float) – A constant to avoid the division zero error.
consbn (torch.nn.Module) – If none, the raw feature will be used as the consequent input; If a pytorch module, then the consequent input will be the output of the given module. If you wish to use the BN technique we mentioned in Models & Technique, you can set
precons=nn.BatchNorm1d(in_dim).
- reset_parameters(self)
Re-initialize all parameters, including both consequent and antecedent parts.
- forward(self, X, get_frs=False)
- Parameters
X (torch.tensor) – Input matrix with the size of \([N, D]\), where \(N\) is the number of samples.
get_frs (bool) – If true, the firing levels (the output of the antecedent) will also be returned.
- Returns
If
get_frs=True, return the TSK output \(Y\in \mathbb{R}^{N,C}\) and the antecedent output \(U\in \mathbb{R}^{N,R}\). Ifget_frs=False, only return the TSK output \(Y\).
pytsk.gradient_descent.training
- ur_loss(frs, tau=0.5)
The uniform regularization (UR) proposed by Cui et al. [3]. UR loss is computed as \(\ell_{UR} = \sum_{r=1}^R (\frac{1}{N}\sum_{n=1}^N f_{n,r} - \tau)^2\), where \(f_{n,r}\) represents the firing level of the \(n\)-th sample on the \(r\)-th rule.
- Parameters
frs (torch.tensor) – The firing levels (output of the antecedent) with the size of \([N, R]\), where \(N\) is the number of samples, \(R\) is the number of ruels.
tau (float) – The expectation \(\tau\) of the average firing level for each rule. For a \(C\)-class classification problem, we recommend setting \(\tau\) to \(1/C\), for a regression problem, \(\tau\) can be set as \(0.5\).
- Returns
A scale value, representing the UR loss.
- class Wrapper(model, optimizer, criterion, batch_size=512, epochs=1, callbacks=None, label_type='c', device='cpu', reset_param=True, ur=0, ur_tau=0.5, **kwargs)
This class provide a training framework for beginners to train their fuzzy neural networks.
- Parameters
model (torch.nn.Module) – The pre-defined TSK model.
optimizer (torch.Optimizer) – Pytorch optimizer.
torch.nn._Loss – Pytorch loss. For example,
torch.nn.CrossEntropyLoss()for classification tasks, andtorch.nn.MSELoss()for regression tasks.batch_size (int) – Batch size during training & prediction.
epochs (int) – Training epochs.
callbacks ([Callback]) – List of callbacks.
label_type (str) – Label type, “c” or “r”, when
label_type="c", label’s dtype will be changed to “int64”, whenlabel_type="r", label’s dtype will be changed to “float32”.
>>> from pytsk.gradient_descent import antecedent_init_center, AntecedentGMF, TSK, EarlyStoppingACC, EvaluateAcc, Wrapper >>> from sklearn.model_selection import train_test_split >>> from sklearn.metrics import accuracy_score >>> from sklearn.datasets import make_classification >>> from sklearn.preprocessing import StandardScaler >>> from torch.optim import AdamW >>> import torch.nn as nn >>> # ----------------- define data ----------------- >>> X, y = make_classification(random_state=0) >>> x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3) >>> ss = StandardScaler() >>> x_train = ss.fit_transform(x_train) >>> x_test = ss.transform(x_test) >>> # ----------------- define TSK model ----------------- >>> n_rule = 10 # define number of rules >>> n_class = 2 # define output dimension >>> order = 1 # first-order TSK is used >>> consbn = True # consbn tech is used >>> weight_decay = 1e-8 # weight decay for pytorch optimizer >>> lr = 0.01 # learning rate for pytorch optimizer >>> init_center = antecedent_init_center(x_train, y_train, n_rule=n_rule) # obtain the initial antecedent center >>> gmf = AntecedentGMF(in_dim=x_train.shape[1], n_rule=n_rule, high_dim=True, init_center=init_center) # define antecedent >>> model = TSK(in_dim=x_train.shape[1], out_dim=n_class, n_rule=n_rule, antecedent=gmf, order=order, consbn=consbn) # define TSK >>> # ----------------- define optimizers ----------------- >>> ante_param, other_param = [], [] >>> for n, p in model.named_parameters(): >>> if "center" in n or "sigma" in n: >>> ante_param.append(p) >>> else: >>> other_param.append(p) >>> optimizer = AdamW( >>> [{'params': ante_param, "weight_decay": 0}, # antecedent parameters usually don't need weight_decay >>> {'params': other_param, "weight_decay": weight_decay},], >>> lr=lr >>> ) >>> # ----------------- split 20% data for earlystopping ----------------- >>> x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2) >>> # ----------------- define the earlystopping callback ----------------- >>> EACC = EarlyStoppingACC(x_val, y_val, verbose=1, patience=40, save_path="tmp.pkl") # Earlystopping >>> TACC = EvaluateAcc(x_test, y_test, verbose=1) # Check test acc during training >>> # ----------------- train model ----------------- >>> wrapper = Wrapper(model, optimizer=optimizer, criterion=nn.CrossEntropyLoss(), >>> epochs=300, callbacks=[EACC, TACC], ur=0, ur_tau=1/n_class) # define training wrapper, ur weight is set to 0 >>> wrapper.fit(x_train, y_train) # fit >>> wrapper.load("tmp.pkl") # load best model saved by EarlyStoppingACC callback >>> y_pred = wrapper.predict(x_test).argmax(axis=1) # predict, argmax for extracting classfication label >>> print("[TSK] ACC: {:.4f}".format(accuracy_score(y_test, y_pred))) # print ACC
- train_on_batch(self, input, target)
Define how to update a model with one batch of data. This method can be overwrite for custom training strategy.
- Parameters
input (torch.tensor) – Feature matrix with the size of \([N,D]\), \(N\) is the number of samples, \(D\) is the input dimension.
target (torch.tensor) – Target matrix with the size of \([N,C]\), \(C\) is the output dimension.
- fit(X, y)
Train the
modelwith numpy array.- Parameters
X (numpy.array) – Feature matrix \(X\) with the size of \([N, D]\).
y (numpy.array) – Label matrix \(Y\) with the size of \([N, C]\), for classification task, \(C=1\), for regression task, \(C\) is the number of the output dimension of
model.
- fit_loader(self, train_loader)
Train the
modelwith user-defined pytorch dataloader.- Parameters
train_loader (torch.utils.data.DataLoader) – Data loader, the output of the loader should be corresponding to the inputs of
train_on_batch. For example, if dataloader has two output, thentrain_on_batchshould also have two inputs.
- predict(self, X, y=None)
Get the prediction of the model.
- Parameters
X (numpy.array) – Feature matrix \(X\) with the size of \([N, D]\).
y – Not used.
- Returns
Prediction matrix \(\hat{Y}\) with the size of \([N, C]\), \(C\) is the output dimension of the
model.
- predict_proba(self, X, y=None)
For classification problem only, need
label_type="c", return the prediction after softmax.- Parameters
X (numpy.array) – Feature matrix \(X\) with the size of \([N, D]\).
y – Not used.
- Returns
Prediction matrix \(\hat{Y}\) with the size of \([N, C]\), \(C\) is the output dimension of the
model.
- save(self, path)
Save model.
- Parameters
path (str) – Model save path.
- load(self, path)
Load model.
- Parameters
path (str) – Model save path.
pytsk.gradient_descent.callbacks
- class Callback
Similar as the callback class in Keras, our package provides a simplified version of callback, which allow users to monitor metrics during the training. We strongly recommend uses to custom their callbacks, here we provide two examples,
EvaluateAccandEarlyStoppingACC.- on_batch_begin(self, wrapper)
Will be called before each batch.
- on_batch_end(self, wrapper)
Will be called after each batch.
- on_epoch_begin(self, wrapper)
Will be called before each epoch.
- on_epoch_end(self, wrapper)
Will be called after each epoch.
- class EvaluateAcc(X, y, verbose=0)
Evaluate the accuracy during training.
- Parameters
X (numpy.array) – Feature matrix with the size of \([N, D]\).
y (numpy.array) – Label matrix with the size of \([N, 1]\).
- on_epoch_end(self, wrapper)
>>> def on_epoch_end(self, wrapper): >>> cur_log = {} >>> y_pred = wrapper.predict(self.X).argmax(axis=1) >>> acc = accuracy_score(y_true=self.y, y_pred=y_pred) >>> cur_log["epoch"] = wrapper.cur_epoch >>> cur_log["acc"] = acc >>> self.logs.append(cur_log) >>> if self.verbose > 0: >>> print("[Epoch {:5d}] Test ACC: {:.4f}".format(cur_log["epoch"], cur_log["acc"]))
- class EarlyStoppingACC(X, y, patience=1, verbose=0, save_path=None)
Early-stopping by classification accuracy.
- Parameters
X (numpy.array) – Feature matrix with the size of \([N, D]\).
y (numpy.array) – Label matrix with the size of \([N, 1]\).
patience (int) – Number of epochs with no improvement after which training will be stopped.
verbose (int) – verbosity mode.
save_path (str) – If
save_path=None, do not save models, else save the model with the best accuracy to the given path.
- on_epoch_end(self, wrapper)
Calculate the validation accuracy and determine whether to stop training.
>>> def on_epoch_end(self, wrapper): >>> cur_log = {} >>> y_pred = wrapper.predict(self.X).argmax(axis=1) >>> acc = accuracy_score(y_true=self.y, y_pred=y_pred) >>> if acc > self.best_acc: >>> self.best_acc = acc >>> self.cnt = 0 >>> if self.save_path is not None: >>> wrapper.save(self.save_path) >>> else: >>> self.cnt += 1 >>> if self.cnt > self.patience: >>> wrapper.stop_training = True >>> cur_log["epoch"] = wrapper.cur_epoch >>> cur_log["acc"] = acc >>> cur_log["best_acc"] = self.best_acc >>> self.logs.append(cur_log) >>> if self.verbose > 0: >>> print("[Epoch {:5d}] EarlyStopping Callback ACC: {:.4f}, Best ACC: {:.4f}".format(cur_log["epoch"], cur_log["acc"], cur_log["best_acc"]))
pytsk.gradient_descent.utils
- check_tensor(tensor, dtype)
Convert
tensorinto adtypetorch.Tensor.- Parameters
tensor (numpy.array/torch.tensor) – Input data.
dtype (str) – PyTorch dtype string.
- Returns
A
dtypetorch.Tensor.
- reset_params(model)
Reset all parameters in
model.- Parameters
model (torch.nn.Module) – Pytorch model.
- class NumpyDataLoader(*inputs)
Convert numpy arrays into a dataloader.
- Parameters
inputs (numpy.array) – Numpy arrays.